Jiangjie Chen
Jiangjie Chen
Home
News
Experience
Awards
Featured
Recent
Topics
Publications
CV
Light
Dark
Automatic
Benchmark
DetectBench: Can Large Language Model Detect and Piece Together Implicit Evidence?
We introduce DetectBench, a benchmark for testing LLMs’ evidence detection in long contexts, and demonstrates that while existing LLMs lag behind human performance, the proposed Detective Reasoning Prompt and Finetuning methods can significantly improve their evidence detection and reasoning capabilities.
Zhouhong Gu
,
Lin Zhang
,
Xiaoxuan Zhu
,
Jiangjie Chen
,
Wenhao Huang
,
Yikai Zhang
,
Shusen Wang
,
Zheyu Ye
,
Yan Gao
,
Hongwei Feng
,
Yanghua Xiao
PDF
Cite
Code
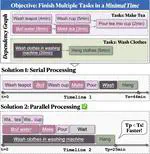
TimeArena: Shaping Efficient Multitasking Language Agents in a Time-Aware Simulation
TimeArena enhances LLMs with temporal dynamics for better multitasking, showing advanced models like GPT-4 still trail behind human temporal awareness.
Yikai Zhang
,
Siyu Yuan
,
Caiyu Hu
,
Kyle Richardson
,
Yanghua Xiao
,
Jiangjie Chen
PDF
Cite
Project
TravelPlanner: A Benchmark for Real-World Planning with Language Agents
We introduced TravelPlanner, a benchmark for assessing language agents’ planning abilities, showing that even advanced models like GPT-4 face difficulties with complex tasks.
Jian Xie
,
Kai Zhang
,
Jiangjie Chen
,
Tinghui Zhu
,
Renze Lou
,
Yuandong Tian
,
Yanghua Xiao
,
Yu Su
PDF
Cite
Dataset
Code
Demo
Put Your Money Where Your Mouth Is: Evaluating Strategic Planning and Execution of LLM Agents in an Auction Arena
We propose AucArena to tests LLMs in auctions, showing they can strategize but with variable success, indicating potential for enhancement.
Jiangjie Chen
,
Siyu Yuan
,
Rong Ye
,
Bodhisattwa Prasad Majumder
,
Kyle Richardson
PDF
Cite
Demo
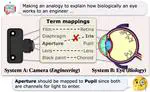
Beneath Surface Similarity: Large Language Models Make Reasonable Scientific Analogies after Structure Abduction
We propose a scientific analogical reasoning benchmark with structure abduction, SCAR, and show that large language models make reasonable scientific analogies after structure abduction.
Siyu Yuan
,
Jiangjie Chen
,
Xuyang Ge
,
Yanghua Xiao
,
Deqing Yang
PDF
Cite
Code
Distilling Script Knowledge from Large Language Models for Constrained Language Planning
We propose an over-generate-then-filter approach to improve large language models (LLMs) on constrained language planning, and use it to distill a novel constrained language planning dataset, CoScript.
Siyu Yuan
,
Jiangjie Chen
,
Ziquan Fu
,
Xuyang Ge
,
Soham Shah
,
Charles Robert Jankowski
,
Yanghua Xiao
,
Deqing Yang
PDF
Cite
Poster
Slides
Code
Say What You Mean! Large Language Models Speak Too Positively about Negative Commonsense Knowledge
We find that large language models (LLMs) speak too positively about negative commonsense knowledge, which is caused by statistical shortcuts and negation reporting bias from language modeling pre-training.
Jiangjie Chen
,
Wei Shi
,
Ziquan Fu
,
Sijie Cheng
,
Lei Li
,
Yanghua Xiao
PDF
Cite
Poster
Slides
Code
E-KAR: A Benchmark for Rationalizing Natural Language Analogical Reasoning
We benchmark knowledge-intensive analogical reasoning with human-annotated explanations.
Jiangjie Chen
,
Rui Xu
,
Ziquan Fu
,
Wei Shi
,
Zhongqiao Li
,
Xinbo Zhang
,
Changzhi Sun
,
Lei Li
,
Yanghua Xiao
,
Hao Zhou
PDF
Cite
Project
Poster
Slides
Video
DOI
Cite
×