Jiangjie Chen
Jiangjie Chen
Home
News
Experience
Awards
Featured
Recent
Topics
Publications
CV
Light
Dark
Automatic
LLM Analysis
How Easily do Irrelevant Inputs Skew the Responses of Large Language Models?
We study how LLMs handle irrelevant information and find they struggle with content that is semantically related but ultimately not pertinent, highlighting the limitations of current systems in filtering out such distractions.
Siye Wu
,
Jian Xie
,
Jiangjie Chen
,
Tinghui Zhu
,
Kai Zhang
,
Yanghua Xiao
PDF
Cite
Code
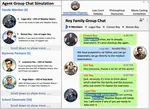
Agent Group Chat: An Interactive Group Chat Simulacra For Better Eliciting Collective Emergent Behavior
We propose a simulation to study language’s influence on collective behavior by having agents engage in free chat within various narrative scenarios, with findings suggesting that greater information exchange promotes more orderly and meaningful emergent behaviors.
Zhouhong Gu
,
Xiaoxuan Zhu
,
Haoran Guo
,
Lin Zhang
,
Yin Cai
,
Hao Shen
,
Jiangjie Chen
,
Zheyu Ye
,
Yifei Dai
,
Yan Gao
,
Yao Hu
,
Hongwei Feng
,
Yanghua Xiao
PDF
Cite
Code
Put Your Money Where Your Mouth Is: Evaluating Strategic Planning and Execution of LLM Agents in an Auction Arena
We propose AucArena to tests LLMs in auctions, showing they can strategize but with variable success, indicating potential for enhancement.
Jiangjie Chen
,
Siyu Yuan
,
Rong Ye
,
Bodhisattwa Prasad Majumder
,
Kyle Richardson
PDF
Cite
Demo
Adaptive Chameleon or Stubborn Sloth: Revealing the Behavior of Large Language Models in Knowledge Conflicts
We present the first comprehensive and controlled investigation into the behavior of large language models when encountering knowledge conflicts.
Jian Xie
,
Kai Zhang
,
Jiangjie Chen
,
Renze Lou
,
Yu Su
PDF
Cite
Code
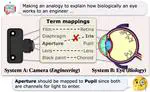
Beneath Surface Similarity: Large Language Models Make Reasonable Scientific Analogies after Structure Abduction
We propose a scientific analogical reasoning benchmark with structure abduction, SCAR, and show that large language models make reasonable scientific analogies after structure abduction.
Siyu Yuan
,
Jiangjie Chen
,
Xuyang Ge
,
Yanghua Xiao
,
Deqing Yang
PDF
Cite
Code
Say What You Mean! Large Language Models Speak Too Positively about Negative Commonsense Knowledge
We find that large language models (LLMs) speak too positively about negative commonsense knowledge, which is caused by statistical shortcuts and negation reporting bias from language modeling pre-training.
Jiangjie Chen
,
Wei Shi
,
Ziquan Fu
,
Sijie Cheng
,
Lei Li
,
Yanghua Xiao
PDF
Cite
Poster
Slides
Code
Cite
×