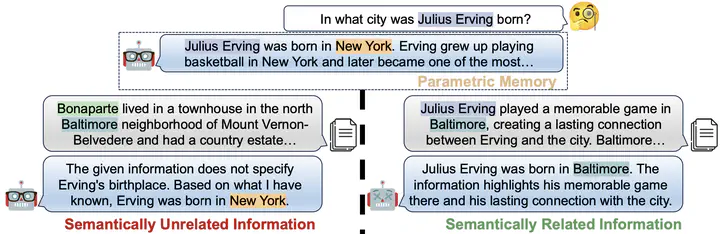
 An example of how semantically related irrelevant information distracts LLMs. LLMs are misled by the information due to over-reasoning.
An example of how semantically related irrelevant information distracts LLMs. LLMs are misled by the information due to over-reasoning.
Abstract
By leveraging the retrieval of information from external knowledge databases, Large Language Models (LLMs) exhibit enhanced capabilities for accomplishing many knowledge-intensive tasks. However, due to the inherent flaws of current retrieval systems, there might exist irrelevant information within those retrieving top-ranked passages. In this work, we present a comprehensive investigation into the robustness of LLMs to different types of irrelevant information under various conditions. We initially introduce a framework to construct high-quality irrelevant information that ranges from semantically unrelated, partially related, and related to questions. Furthermore, our analysis demonstrates that the constructed irrelevant information not only scores highly on similarity metrics, being highly retrieved by existing systems, but also bears semantic connections to the context. Our investigation reveals that current LLMs still face challenges in discriminating highly semantically related information and can be easily distracted by these irrelevant yet misleading contents. Besides, we also find that current solutions for handling irrelevant information have limitations in improving the robustness of LLMs to such distractions.
Jiangjie Chen
Researcher
His research interests mainly include large models and their reasoning abilities.