 Examples of annotations from SQuAD that illustrate the partial annotation problem.
Examples of annotations from SQuAD that illustrate the partial annotation problem.
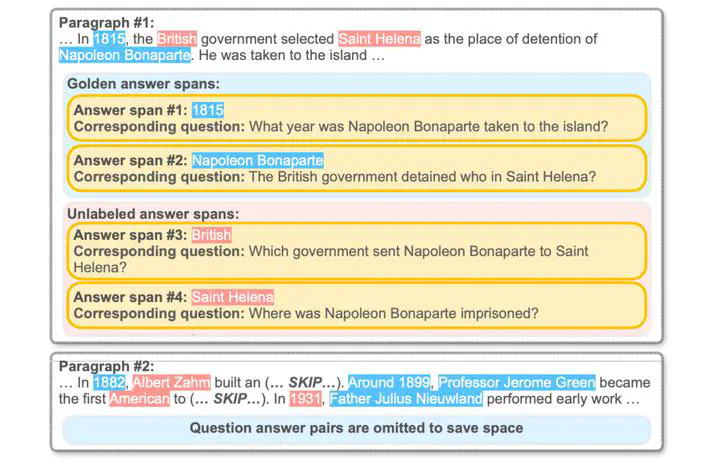
Abstract
Automatic Answer span Extraction (AE) focuses on identifying key information from paragraphs that can be asked. It has been used to facilitate downstream question generation tasks or data augmentation for question answering. Current work of AE heavily relies on the annotated answer spans from Machine Reading Comprehension (MRC) datasets. However, these methods suffer from the partial annotation problem due to the annotation protocols of MRC tasks. To tackle this problem, we propose SCOPE, a Structured Context graph network with Positive-unlabeled learning. SCOPE first represents the paragraph by constructing a graph with both syntactic and semantic edges, then adopts a unified pointer network for answer span identification. SCOPE narrows the discrenpency between AE and MRC by formulating AE as a Positive-unlabeled (PU) learning problem, thus recovering more answer spans from paragraphs. To evaluate newly extracted spans without annotation, we also present an automatic metric from the perspective of question answering and text summarization, which correlates well with human judgments. Comprehensive experiments on both AE and downstream tasks demonstrate the effectiveness of our proposed framework.
Jiangjie Chen
Researcher
His research interests mainly include large models and their reasoning abilities.