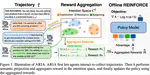
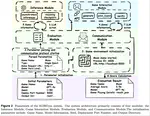
Qiying Yu,
Zheng Zhang,
Ruofei Zhu,
Yufeng Yuan,
Xiaochen Zuo,
Yu Yue,
Tiantian Fan,
Gaohong Liu,
Lingjun Liu,
Xin Liu,
Haibin Lin,
Zhiqi Lin,
Bole Ma,
Guangming Sheng,
Yuxuan Tong,
Chi Zhang,
Mofan Zhang,
Wang Zhang,
Hang Zhu,
Jinhua Zhu,
Jiaze Chen,
Jiangjie Chen,
Chengyi Wang,
Hongli Yu,
Weinan Dai,
Yuxuan Song,
Xiangpeng Wei,
Hao Zhou,
Jingjing Liu,
Wei-Ying Ma,
Ya-Qin Zhang,
Lin Yan,
Mu Qiao,
Yonghui Wu,
Mingxuan Wang