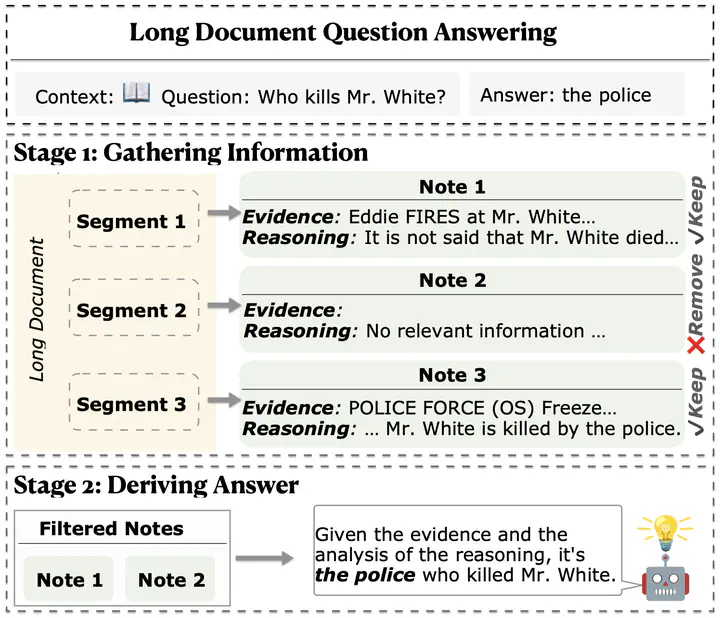
 This picture illustrates the use of short-context models to tackle long document question answering tasks in SEGMENT+. The process begins by gathering relevant context from the document for a specific question. Only notes labeled ‘keep’ are used as the context to derive the final answer, avoiding noise.
This picture illustrates the use of short-context models to tackle long document question answering tasks in SEGMENT+. The process begins by gathering relevant context from the document for a specific question. Only notes labeled ‘keep’ are used as the context to derive the final answer, avoiding noise.
Abstract
There is a growing interest in expanding the input capacity of language models (LMs) across various domains. However, simply increasing the context window does not guarantee robust performance across diverse long-input processing tasks, such as understanding extensive documents and extracting detailed information from lengthy and noisy data. In response, we introduce SEGMENT+, a general framework that enables LMs to handle extended inputs within limited context windows efficiently. SEGMENT+ utilizes structured notes and a filtering module to manage information flow, resulting in a system that is both controllable and interpretable. Our extensive experiments across various model sizes, focusing on long-document question-answering and Needle-in-a-Haystack tasks, demonstrate the effectiveness of SEGMENT+ in improving performance.
Jiangjie Chen
Researcher
His research interests mainly include large models and their reasoning abilities.