MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
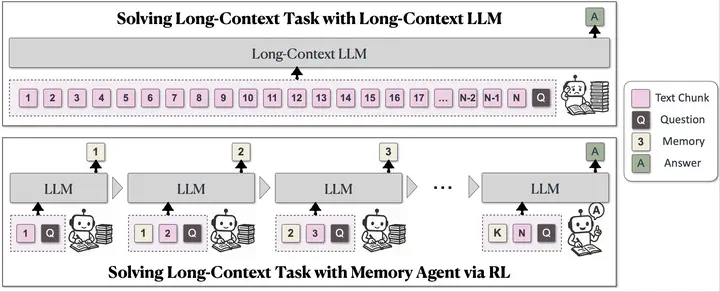 MemAgent: A multi-conv RL-based memory agent for handling extremely long documents with linear complexity.
MemAgent: A multi-conv RL-based memory agent for handling extremely long documents with linear complexity.
Abstract
The paper introduces MemAgent, a novel approach to handling extremely long documents in language models. The system reads text in segments and updates the memory using an overwrite strategy and extends the DAPO algorithm for training. Key achievements include extrapolating from an 8K context trained on 32K text to a 3.5M QA task with performance loss < 5% and achieving 95%+ in 512K RULER test. This represents significant progress in long-context language model capabilities, demonstrating substantial scalability improvements through reinforcement learning-based memory management with multi-conversation generation training.
Type
Publication
Preprint
Jiangjie Chen
Researcher
His research interests mainly include large models and their reasoning abilities.