LOREN: Logic-Regularized Reasoning for Interpretable Fact Verification
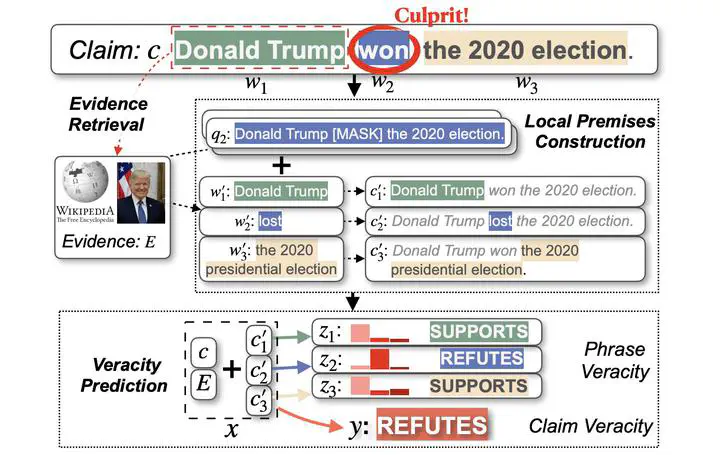 LOREN not only makes the final verification but also finds the culprit phrase that causes the claim’s falsity.
LOREN not only makes the final verification but also finds the culprit phrase that causes the claim’s falsity.
Abstract
Given a natural language statement, how to verify its veracity against a large-scale textual knowledge source like Wikipedia? Most existing neural models make predictions without giving clues about which part of a false claim goes wrong. In this paper, we propose LOREN, an approach for interpretable fact verification. We decompose the verification of the whole claim at phrase-level, where the veracity of the phrases serves as explanations and can be aggregated into the final verdict according to logical rules. The key insight of LOREN is to represent claim phrase veracity as three-valued latent variables, which are regularized by aggregation logical rules. The final claim verification is based on all latent variables. Thus, LOREN enjoys the additional benefit of interpretability – it is easy to explain how it reaches certain results with claim phrase veracity. Experiments on a public fact verification benchmark show that LOREN is competitive against previous approaches while enjoying the merit of faithful and accurate interpretability.
Jiangjie Chen
Researcher
His research interests mainly include large models and their reasoning abilities.