DEEPER Insight into Your User: Directed Persona Refinement for Dynamic Persona Modeling
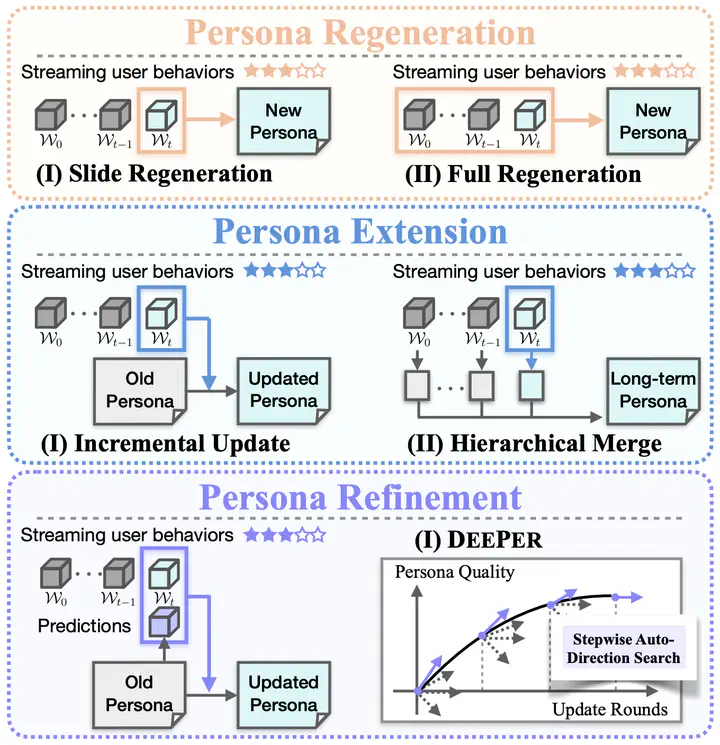 Comparison of dynamic persona modeling paradigms: Regeneration replaces personas, and Extension adds to them, but neither ensures optimization. Our DEEPER, based on Refinement paradigm, uses discrepancies between user behavior and model predictions to identify update directions for continuous optimization.
Comparison of dynamic persona modeling paradigms: Regeneration replaces personas, and Extension adds to them, but neither ensures optimization. Our DEEPER, based on Refinement paradigm, uses discrepancies between user behavior and model predictions to identify update directions for continuous optimization.
Abstract
To advance personalized applications such as recommendation systems and user behavior prediction, recent research increasingly adopts large language models (LLMs) for human -readable persona modeling. In dynamic real -world scenarios, effective persona modeling necessitates leveraging streaming behavior data to continually optimize user personas. However, existing methods -whether regenerating personas or incrementally extending them with new behaviors -often fail to achieve sustained improvements in persona quality or future behavior prediction accuracy. To address this, we propose DEEPER, a novel approach for dynamic persona modeling that enables continual persona optimization. Specifically, we enhance the model’s direction -search capability through an iterative reinforcement learning framework, allowing it to automatically identify effective update directions and optimize personas using discrepancies between user behaviors and model predictions. Extensive experiments on dynamic persona modeling involving 4800 users across 10 domains highlight the superior persona optimization capabilities of DEEPER, delivering an impressive 32.2% average reduction in user behavior prediction error over four update rounds -outperforming the best baseline by a remarkable 22.92%.
Jiangjie Chen
Researcher
His research interests mainly include large models and their reasoning abilities.