Put Your Money Where Your Mouth Is: Evaluating Strategic Planning and Execution of LLM Agents in an Auction Arena
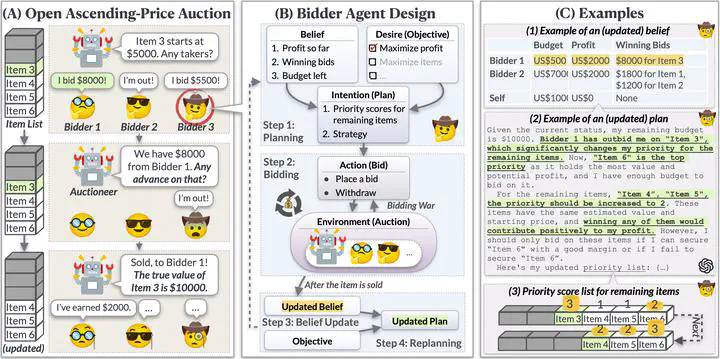 An illustration of AUCARENA: a multi-round, open ascending-price auction, the bidder agent architecture, and examples of updated beliefs and plans.
An illustration of AUCARENA: a multi-round, open ascending-price auction, the bidder agent architecture, and examples of updated beliefs and plans.
Abstract
Can Large Language Models (LLMs) simulate human behavior in complex environments? LLMs have recently been shown to exhibit advanced reasoning skills but much of NLP evaluation still relies on static benchmarks. Answering this requires evaluation environments that probe strategic reasoning in competitive, dynamic scenarios that involve long-term planning. We introduce AucArena, a novel simulation environment for evaluating LLMs within auctions, a setting chosen for being highly unpredictable and involving many skills related to resource and risk management, while also being easy to evaluate. We conduct several controlled simulations using state-of-the-art LLMs as bidding agents. We find that through simple prompting, LLMs do indeed demonstrate many of the skills needed for effectively engaging in auctions (e.g., managing budget, adhering to long-term goals and priorities), skills that we find can be sharpened by explicitly encouraging models to be adaptive and observe strategies in past auctions. These results are significant as they show the potential of using LLM agents to model intricate social dynamics, especially in competitive settings. However, we also observe considerable variability in the capabilities of individual LLMs. Notably, even our most advanced models (GPT-4) are occasionally surpassed by heuristic baselines and human agents, highlighting the potential for further improvements in the design of LLM agents and the important role that our simulation environment can play in further testing and refining agent architectures.
Jiangjie Chen
Researcher
His research interests mainly include large models and their reasoning abilities.