ARIA: Training Language Agents with Intention-Driven Reward Aggregation
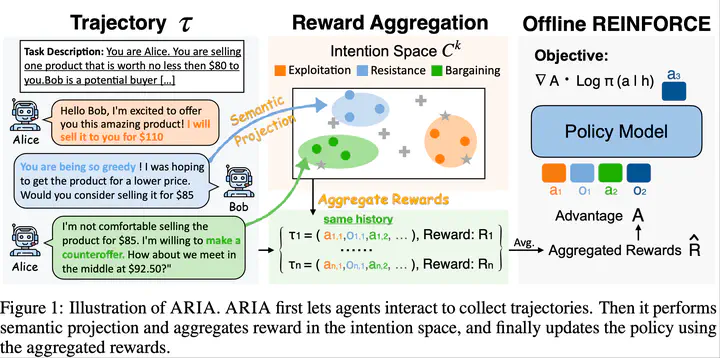 ARIA framework: Aggregating rewards in intention space for efficient language agent training.
ARIA framework: Aggregating rewards in intention space for efficient language agent training.
Abstract
The training of language agents for open-ended environments presents significant challenges, particularly due to the complexity of action spaces that can be formulated as joint distributions over tokens, resulting in exponentially large action spaces. In such scenarios, traditional policy optimization methods often struggle with high variance and inefficient exploration, which impedes effective learning. To address these challenges, we introduce ARIA, a novel training framework that Aggregates Rewards in Intention space to enable efficient and effective language Agents training. Our key insight is that natural language actions often need to convey clear intentions, allowing us to project them into a lower-dimensional intention space. This projection enables us to aggregate step-wise rewards into intention-level rewards, where semantically similar actions are clustered and assigned shared rewards. This reduces the variance of policy gradient estimations and allows for more stable and sample-efficient training. Additionally, it allows us to leverage domain knowledge to design intention-level rewards, further improving training efficiency. Experimental results on four representative digital environments demonstrate that ARIA substantially improves the performance of language agents, achieving an average improvement of 9.95% across different base models and environments compared to traditional training methods.
Jiangjie Chen
Researcher
His research interests mainly include large models and their reasoning abilities.